BeatifulSoup简介
灵活又方便的解析网页解析库,处理高效,支持多种解析器。
利用它不用编写正则表达式即可方便地实现网页信息的提取。
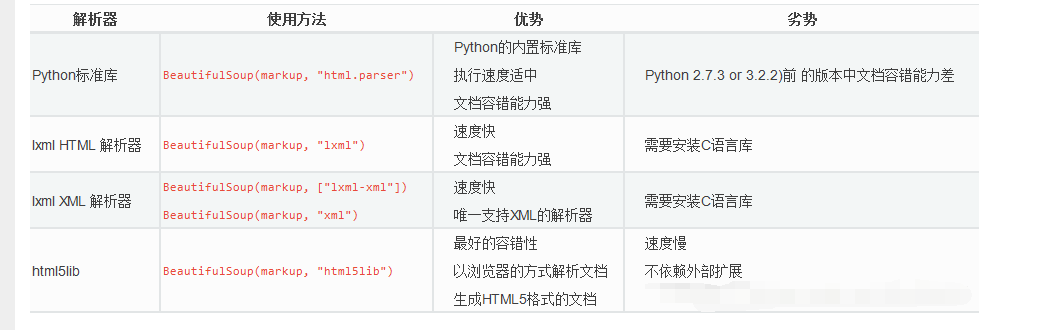
BeatifulSoup主要解析器
BeatifulSoup演示案例
aa.html
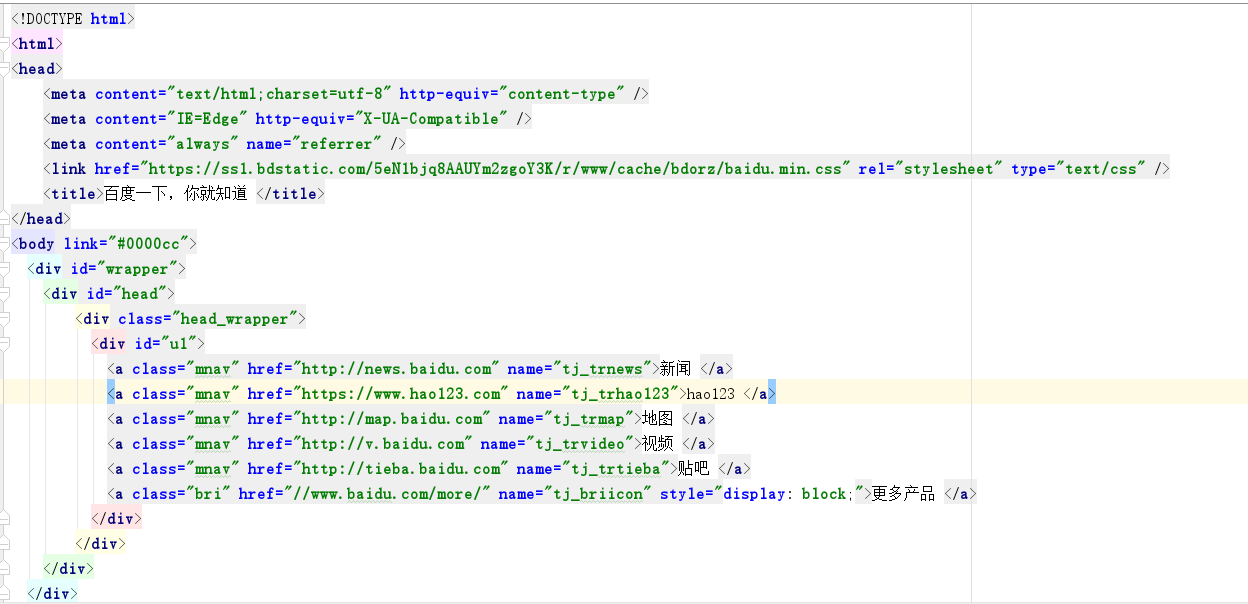
demo.py

BeatifulSoup4的四大种类
BeautifulSoup4将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
Tag
通俗的讲就是HTML里的标签,可以利用soup加标签名轻松获得标签的内容,但是查找的内容是第一个符合要求的标签
属性:name、attrs
NavigableString
标签的文字部分的内容,用.string获取
BeautifulSoup
表示一个文档的内容
Comment
特殊类型的NavigableString 对象,其输出的内容不包括注释符号。
遍历文档树
- .contents: 获取Tag的所有子节点,返回一个list
- .children: 获取Tag的所有子节点,返回一个生成器
- .descendants:获取Tag的所有子孙节点
- .strings:如果Tag包含多个字符串,即在子孙节点中有内容,可以用此获取,而后进行遍历
- .stripped_strings:与strings用法一致,只不过可以去除掉那些多余的空白内容
- .parent:获取Tag的父节点
- .previous_sibling:获取当前Tag的上一个节点,属性通常是字符串或空白,真实结果是当前标签与上一个标签之间的顿号和换行符
- .next_sibling:获取当前Tag的下一个节点,属性通常是字符串或空白,真是结果是当前标签与下一个标签之间的顿号与换行符
- .previous_siblings:获取当前Tag的上面所有的兄弟节点,返回一个生成器
- .next_siblings:获取当前Tag的下面所有的兄弟节点,返回一个生成器
- .previous_element:获取解析过程中上一个被解析的对象(字符串或tag),可能与previous_sibling相同,但通常是不一样的
- .next_element:获取解析过程中下一个被解析的对象(字符串或tag),可能与next_sibling相同,但通常是不一样的
- .previous_elements:返回一个生成器,可以向前访问文档的解析内容
- .next_elements:返回一个生成器,可以向后访问文档的解析内容
- .has_attr:判断Tag是否包含属性
搜索文档树
1 | from bs4 import BeautifulSoup |
css选择器
通过bs.select()方法选取具有对应样式的元素
